Introduction et notions de base
Ce cours théorique a pour but de vous fournir les principales notions de toute communication entre plusieurs machines utilisant la suite de protocoles TCP/IP. Ces protocoles sont aujourd’hui un standard reconnu et utilisé partout dans le monde et quelques soient les réseaux. Après avoir étudié ce cours, vous aurez acquis une bonne compréhension des technologies modernes de communication réseau entre deux machines. Bonne lecture et bonne chance…
Dans toute communication réseau, il y a un client et un serveur. Le client est le système qui va demander à établir une connection ; le serveur celui qui va non pas uniquement répondre à cette demande, mais aussi l’accepter. L’état de client est simple : il doit juste être capable d’envoyer des demandes de connection. Par contre, l’état de serveur est beaucoup plus complexe : un serveur doit pouvoir accepter (ou refuser) des connections, les gérer (envoi, réception d’information, erreurs éventuelles…) Mais attention : un système qui refuse une connection n’est pas forcément en état de serveur : des clients n’ont pas à traiter des demandes de connection, ils doivent les refuser.
Pour gérer ces demandes de connection sur un serveur, on a mis en place des applications logicielles délivrant un service. Le rôle de ces applications va donc être d’accepter (ou refuser) des connections et de les traiter. Ces applications seront appelées des applications serveurs qui délivrent un service. Pour simplifier, une machine faisant fonctionner des applications serveurs est appelée serveur : son unique rôle est de gérer des demandes de connection, et non pas d’en émettre la demande.
Ces demandes sont réservées au client. Du même principe qu’il a été crée des applications serveurs pour gérer des connections, il a été développé des applications client pour émettre des demandes de connection.
Exemple : Lorsque l’on consulte une page html sur le Web, nous nous connectons à une application serveur, par exemple Apache ou IIS, cette application va délivrer un service http. Pour se connecter à ce serveur, nous allons utiliser une application client : Netscape, Internet Explorer, Mozilla…
Remarque : Nous avons vu qu’un serveur peut refuser une demande de connection. En effet, une connection ne s’effectue jamais en sens unique : toujours à double sens. Pour que deux machines A et B puissent communiquer entre elles, il faut qu’elles aient les deux accepté la demande de connection : A est connecté à B et B à A.
2. Protocoles
Si les données étaient transmises de façon anarchique, sans aucune règle concernant leur construction et leur transmission, aucune machine ne serait capable de communiquer avec une autre. Pour que les machines puissent se comprendre, il faut standardiser la façon dont elles communiquent entre elles. Cette standardisation s’effectue grâce à la mise en place des protocoles, qui vont chacun avoir leur rôle dans la communication réseau.
Pour pouvoir communiquer, une machine a besoin d’ouvrir des ports. Un port est en fait une sorte d’ouverture logicielle sur la machine, indépendante de tout aspect matériel. Une machine en compte en tout 65536 (codé sur 16 bits). Il faut cependant noter que le port 0 est invalide. Donc les possibilités vont de 1 à 65535. Lorsqu’une machine A est connectée à B, un port est ouvert sur A et un autre sur B (ils peuvent être différents). Alors qu’une application serveur ouvre un port en permanence pour traiter d’éventuels demande de connection, une application cliente peut se permettre d’en ouvrir qu’au moment où elle en a besoin (elle ne reçoit pas de demande de connection). Si un port est fermé il est absolument impossible de se connecter à lui de l’extérieur. De plus, un port ne peut être utilisé que par une seule application cliente. Pour réglementer et standardiser l’attribution des numéros de ports, certains sont réservés : on utilise le port 80 pour accéder à un serveur http, le 25 pour envoyer des messages par SMTP…). En fait les règles sont très précises : de 1 à 1023, ce sont les services bien connus (ftp, http, telnet…) ; de 1024 à 49151, ce sont les services enregistrés par l’IANA (institut qui contrôle leur usage) ; et de 49152 à 65535, ce sont les services privés, dont l’utilisation n’est pas réglementée.
Remarque : Un port ouvert sur une machine signifie qu’il existe un point d’entrée sur le système. Des serveurs faisant tourner beaucoup d’applications serveurs ont donc un plus fort potentiel de se faire attaquer par un utilisateur malveillant qu’un système très fermé.
Un socket est une interface logicielle qui permet à une application de communiquer avec le réseau. En fait, nous pouvons dire que c’est elle qui relie le port avec l’application. C’est en quelque sorte l’extrémité du réseau par lequel l’application va envoyer ou recevoir les données. A chaque nouvelle connection, un nouveau socket va être crée. C’est lui qui permet de différencier plusieurs connections s’adressant au même port (service).
5. Routage
Pour le moment et pour simplifier nous définirons le routage comme le mécanisme permettant aux information de se déplacer dans un réseau ou à travers plusieurs réseau : passer par des routeurs, des passerelles…
Ø C’est une suite de protocoles ouverts (les sources sont en C) et standardisés, développés indépendamment de toute architecture, ce qui les rends transportable sur toute plateforme. L’adressage est donc commun à toutes les structures.
Ø Ces protocoles sont indépendants de tout support physique du réseau : ils peuvent être utilisés aussi bien sur des réseaux utilisant les technologies : coaxial Ethernet, fibre optique, token-ring, rayon laser, liaison radio (wireless), câble, xDSL…
Ø Pour simplifier, IP va être utilisé pour l’adressage des données transmises, permettant ainsi aux machines relais émettrices et réceptrices d’établir un chemin correct de transmission de données. TCP lui va définir le type d’information : les données, les demandes de connection, demandes de fermeture… Ces deux protocoles forment le noyau d’internet.
Toutes les informations et spécifications techniques relatives aux protocoles réseaux se trouvent dans les RFC (Request For Comment) disponibles un peu partout sur l’Internet. Il suffit dans un moteur de recherche de taper « RFC <le numéro> ». Vous trouverez aussi des liens vers les RFC principales traduites en français, dans notre rubrique lien.
Nous avons vus précédemment le fonctionnement du modèle OSI. La suite de protocole TCP/IP ainsi que les protocoles complémentaires, bien qu’étant différents, ces deux modèles ont beaucoup de points communs. En fait, le modèle OSI a été élaboré après la conception de TCP/IP. Il était censé représenter la manière idéale d’organisation et de conception de communications réseaux. Seulement en observant le modèle TCP/IP, on se rend compte que de nombreux points du modèle OSI sont présents dans TCP/IP. La décomposition en couches successives des tâches de différents niveaux, indépendantes les unes des autres en est un exemple. Comparons ces deux modèles :

Nous pouvons définir le rôle de chaque couche ainsi :
Ø Couche Application : Au plus haut niveau de la hiérarchisation, les utilisateurs lancent un programme qui permet l’accès au réseau. Ce programme utilise le protocole approprié lui permettant l’interface entre les applications, met les données dans un format standard, et gère la création de sessions sur les machines interconnectées dans certains cas.
Ø Couche Transport : La couche transport être responsable du mode de transmission approprié. Cette couche doit garantir l’intégrité des données (gérer les checksum), pouvoir retransmettre les données non ou mal transmise. Ce niveau s’assure donc de la livraison correcte des données.
Ø Couche Internet : Cette couche permet l’adressage des machines sur un réseau. Elle les relie entre elles en quelque sorte. C’est grâce à cela qu’elle peut router les données d’un point à un autre.
Ø Couche réseau Accès : Elle définit les procédures de transmission sur le réseau, mais aussi la manière d’accéder au matériel. Le protocole le plus utilisé est Ethernet.
G. Terminologie
Au niveau de la Couche Accès Réseau, les données sont appelées trames (ou frames). Celles-ci deviennent des datagrammes au niveau de la Couche Internet, puis des paquets (ou des segments) au niveau Transport et enfin des messages (ou un flot de données) au niveau Application.
Au niveau physique lors de la transmission, les données n’étant plus qu’un signal numérique, elles sont appelées signal.
La raison pour laquelle les noms sont différents pour identifier les données aux différents niveaux est que ces données ne sont pas identiques à chaque fois qu’elles sont relayées par un protocole.
Nous voyons que les couches sont indépendantes les unes des autres, et qu’elles ont chacun leur rôle particulier. Prenons un exemple : la couche Internet adresse les machines et donc les données (machine émettrice, et machine destinataire). Les données doivent donc contenir ces adresses pour pouvoir être routées sur le réseau. Les données transmises vont alors contenir en plus des données d’origine, des informations sur le paquet, datagramme… Ces informations constituent ce que l’on appelle un en-tête (header). On les nomme ainsi car ils se situent en tête des données à transmettre. Un en-tête va être ajouté (encapsulé) aux données d’origine, à chaque fois qu’elles vont descendre d’une couche, ou au contraire, être retiré (décapsulé) à chaque fois qu’elles vont monter une couche.
Le but lors d’une émission étant de transformer les données en frame pour être transmises, ou lors d’une réception de fournir les données d’origine, au programme qui traite les demandes de l’utilisateur.
Ainsi, dans le même modèle que l’OSI, nous pouvons voire que lors d’une communication entre deux machines A et B, chaque couche de A va communiquer avec son homologue de B, du même niveau. Lors d’une émission, chaque couche ajoutant son en-tête, les données totales auront une taille beaucoup plus importantes que celles d’origine (plusieurs centaines d’octets). De la même façon, lors d’une réception, chaque couche va prélever les octets qui lui sont propre, pour transmettre les données restantes à la couche supérieure. Chaque couche ne voit donc que les données qui la concernent. Par exemple, l’application de la machine B, ne verra que les données envoyées par A, sans tout le détail de l’acheminement.
Ce principe de montée et de descente à travers les couches peut être résumé par le schéma ci-dessous :
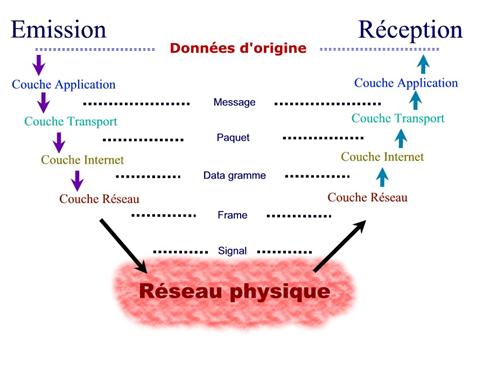
Nous pouvons schématiser le principe d’encapsulation des en-têtes ainsi :
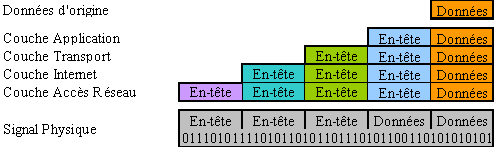
Exemple concret :
Prenons une application
comme un client de messagerie : Outlook par exemple. Lorsque l’on souhaite
envoyer un message, Outlook va convertir notre texte pour le rendre compatible
avec le protocole d'envoi de messages : SMTP. Ce protocole est du niveau
application. Le protocole SMTP en plus de notre message, va ajouter des données
qui permettent à ce protocole d'avoir des paramètres qui lui sont propres (par
exemple l'heure d'envoi du message). Ces données supplémentaires forment
l’en-tête.
Outlook va ensuite passer les données à la pile TCP/IP. La couche transport va
par exemple avoir besoin de préciser l'adresse du port source du serveur, pour
que ce dernier sache traiter le paquet qu'il reçoit (vers quel port envoyer les
données, …). Elle va donc encapsuler son propre en-tête. Puis le paquet est
passé à la couche IP, qui elle même va ajouter son en-tête (elle précisera par
exemple l'adresse Internet (IP) du serveur). Ce va être ensuite au tour de la
couche accès réseau qui va encapsuler son en-tête contenant entre autre
l'adresse de la carte réseau (MAC) de la machine locale censé relayer notre
paquet vers le serveur.
On voit donc qu'à chaque passage par une couche, un en-tête est ajoutée, donnant
des informations utiles pour la couche de même nom distante : la machine
distante va savoir comment traiter les données qu'elle reçoit.
Ces en-têtes sont très importants car suivant l'évolution de TCP/IP, il suffit
de modifier une couche : et donc un en-tête dans un paquet pour que le reste de
l'édifice TCP/IP reste intact. Prenons un exemple : demain, Internet sera
adressé par IPv6 (aujourd'hui IPv4). Ce nouveau protocole contient entre autre
un nouvel adressage sur 128 bits. On pourra alors changer la couche Internet
sans toucher ni à la couche Accès Réseau, ni à la couche Transport et ni non
plus à la couche Application ! Il suffira de modifier lors d'un envoi de paquet
l'en-tête IP : mis au format IPv6. Chaque niveau est indépendant mais sait
évoluer autours de n’importe quel autre, d'où l'importance de séparer chaque
tâche en plusieurs couches.
Enfin, nous pouvons observer que chaque couche ajoute ses propres données. Les
données totales à transmettre ne seront alors plus les mêmes, d'où l'utilité de
changer de nom : ceci précise le paragraphe de terminologie plus haut.
Remarque : La taille des en-têtes dépend du protocole utilisé (quelques mots de 32 bits).
Remarque 2 : Sur un réseau local, les datagrammes transmis sont exactement les mêmes d’un bout à l’autre. Par contre si nous entrons en communication avec un ordinateur connecté sur un autre réseau (par exemple sur l’Internet), du fait que les machines nous relayant (passerelles, routeurs, …) jusqu’à la machine destinatrice auront des adresses MAC différentes (et donc que le protocole ARP ne franchit pas les routeurs : voir le chapitre IV), les frames ne seront pas les mêmes : il y aura des différences dans les en-têtes de la couche Accès Réseau). Par contre, le reste de l’information sera identique d’un bout à l’autre de la communication.
![]()
![]()