
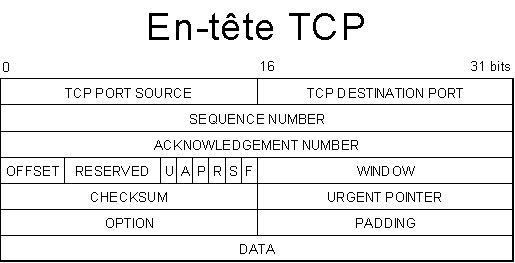
TCP dispose d’un mode de connexion assez fiable et très particulier. En effet, pour qu’une connexion soit établie entre deux machines, il faut que les deux soient d’accord sur l’établissement de la connexion. Le principe est le suivant :
Ø La machine dite cliente (qui désire se connecter, et qui a l’initiative de la connexion) va formuler une demande à la machine dite serveur (qui fait tourner des services attendant des demandes de connexion). Pour cela, elle va envoyer un paquet vide dans lequel sera activé le flag SYN Dans l’en-tête TCP au serveur auquel elle souhaite se connecter. Pour accompagner le flag SYN, elle indiquera aussi son ISN, que l’on nommera x.
Ø Lorsque le serveur reçoit la demande, deux possibilités s’offrent à lui : soit il la refuse : il le fait savoir au client en lui envoyant un paquet TCP avec le flag RST d’activé. Ou alors, il accepte la demande. Il va alors répondre par un paquet avec le flag ACK (il accepte), et également acquitter le paquet précédent (la demande du client). Pour acquitter ce paquet, il va mettre dans le champ ACKNOWLEDGEMENT NUMBER l’ISN du client, incrémenté de 1 : x + 1. La connexion s’établissant dans les deux sens, il va lui aussi formuler sa demande en activant le flag SYN et en fournissant son propre ISN : y.
Ø Le client va alors accepter la demande du serveur. Pour cela, il va activer le flag ACK, et également acquitter le paquet précédent en incrémentant l’ISN du serveur de 1 : y + 1. De même, pour identifier ce paquet, il va mettre comme numéro de séquence son ISN + 1.
Ce mode de connexion est appelé le « three hand shake » : poignée de main en trois temps. Une fois cette procédure achevée, les deux machines sont connectées et vont pouvoir échanger des informations.
On peut résumer cela par ce schéma :
Pour transmettre des données de façon assez sure, TCP comporte un mécanisme d’acquittement, comme nous avons pu l’entrevoir dans la partie précédente. A chaque envoi de données d’une machine, l’autre répond en acquittant les données, et ainsi l’informant de la bonne transmission. En fait à chaque envoi de paquet, une horloge se déclenche. Si l’acquittement ne parvient pas avant que l’horloge ait atteint une certaine valeur, le paquet est retransmit. Il faut donc que les machines conservent une partie de leurs paquets pour être capable de les retransmettre si un problème survient.
Il faut également donner quelques précisions sur un mécanisme appelé de « fenêtre glissante ». En fait, à chaque paquet envoyé, la machine réceptrice ne va pas envoyer d’acquittement : cela surchargerait inutilement le réseau. Comme nous l’avons vu dans la description de l’en-tête, il existe un champ WINDOW, qui permet d’informer l’autre machine du nombre de données que l’on est capable de recevoir sans acquittement. Ce principe évite aussi d’autres problèmes. Il est normal qu’une machine réceptrice mette plus de temps à traiter les données que la machine émettrice. Il ne faut donc pas que la machine émettrice envoie trop de paquets en très peu de temps. Cela provoquerait la perte de données. Grâce à ce mécanisme, la machine émettrice envoie un certain nombre d’octets, et attend l’acquittement de la machine réceptrice pour continuer son envoi.
Après une connexion, la fin de l’établissement de la connection, la communication se passe ainsi :
Ø Le client souhaite envoyer des données (par exemple 40 octets) au serveur. Le serveur a défini une taille de WINDOW de 20 octets (cette mise au point des WINDOW s’est effectuée pendant la connexion, et peut être remise à jour à chaque paquet envoyé par l’une ou l’autre des parties). Le client envoie des paquets contenant 10 octets de données. Il va alors former 4 paquets contenant 10 octets de données chacun. Il va ensuite envoyer le premier paquet. Ce paquet aura comme numéro de séquence ISN-Client+1. Le premier octet de données contenu dans un paquet a toujours comme numéro de séquence ISN-Client+1. Il faut noter qu’une fois la connexion établie, le flag ACK, et le numéro d’acquittement sont toujours renseignés. Le client mettra alors dans ce paquet le flag ACK à 1, et comme numéro d’acquittement le prochain numéro de séquence du serveur que le client s’attend à recevoir. Soit ici ISN-Serveur+1 (en effet, dans cet exemple, le serveur n’envoie pas de données).
Ø Comme le serveur est capable de recevoir 20 octets de données sans acquittement, le client va envoyer un deuxième paquet contenant également 10 octets de données. Ce paquet aura comme numéro de séquence (ISN-Client+1)+10. En effet à ce moment, le client a envoyé 10 octets de plus, donc le numéro de séquence sera incrémenté de 10. Ce paquet contiendra également le flag ACK et comme numéro d’acquittement ISN-Serveur+1
Ø Une fois ces deux paquets envoyés, le client a envoyé au tampon du serveur la taille de la fenêtre. Il n’envoie alors plus de données, et attend l’acquittement du serveur. Le serveur acquitte les données qu’il a reçues en envoyant un paquet sans données, contenant comme seul flag : ACK. Le numéro d’acquittement sera alors ((ISN-Client+1)+10)+10, puisque le client s’attend à recevoir le 21ème octet de donnée, dans le prochain paquet. Le paquet contiendra également comme numéro de séquence ISN-Serveur+1, le serveur n’envoyant pas de données.
Ø Ce processus va alors continuer jusqu’à ce que le client n’ait plus de données à émettre, et que le serveur ait envoyé son dernier acquittement.
Nous pouvons résumer le processus comme suit, en reprenant une connection du paragraphe précédent :
Remarque : En fait, ce processus a été grandement simplifié. Un transfert de données s’effectue à l’aide d’un protocole applicatif tel que ftp, mais ce schéma reflète exactement le mécanisme réel. Il faut ajouter que lorsque le client a fini d’émettre, il va utiliser le flag PUSH, pour que la machine distante transmette immédiatement à l’application serveur les données. Ainsi, le serveur sait lorsqu’un segment de données est terminé (mais pas forcément la connection).
Nous avons vu comment se déroule une connexion, ainsi qu’un échange de données. Il faut maintenant aborder un point important : la clôture de connection. Celle-ci peut se dérouler de deux manières fondamentalement différentes.
1. Clôture cordiale
Ce principe est le même qu’une connection. Pour établir la connection, il faut que les deux parties acceptent de se connecter à l’autre : la connection s’effectue dans les deux sens. Dans le même principe, une clôture de connection s’effectue dans les deux sens. Le mécanisme est le suivant :
Ø Le client a fini d’émettre les données en direction du serveur. Il va alors le signaler au serveur en lui envoyant un paquet vide avec le flag FIN activé. Ce paquet est vide, mais il contiendra le numéro de séquence précédent, incrémenté de la taille des données du paquet précédent (en effet le client n’envoie plus de données, mais il faut différencier le paquet-ci du paquet précédent, donc il aura comme position celle venant juste après les données). Il acceptera également le précédent paquet du serveur, avec le flag ACK, ainsi que le numéro d’acquittement ayant pour valeur la même que le précédent paquet : encore une fois, le serveur n’a jamais envoyé de données.
Ø Le serveur, à réception de ce paquet va alors l’acquitter. Il va donc envoyer un paquet ayant le flag ACK et le numéro d’acquittement sera le précédent numéro de séquence envoyé par le client incrémenté de 1. En effet, il faut différencier cet acquittement des précédents, donc comme dans la phase de connection, on l’incrémente de 1. Le numéro de séquence sera le même que le précédent, puisqu’il n’y a pas de données présentes.
Ø Le serveur va alors faire savoir au client que lui aussi ferme la connection, avec un paquet FIN (le flag ACK est aussi positionné), ayant un numéro de séquence et d’acquittement identique par rapport au précédent (il n’y a pas eu d’envoi de données).
Ø Le client va alors accepter ce paquet avec un paquet comportant le flag ACK et un numéro d’acquittement ayant pour valeur celle du dernier numéro de séquence envoyé par le serveur, incrémenté de 1. Il contiendra également un numéro de séquence : le même que le précédent paquet qu’il a envoyé incrémenté de 1.
C’est donc un mécanisme en 4 étapes qui permet de clôturer une connection.
Résumons cette phase :
Client à ACK num = j | seq = k | FIN à Serveur
Serveur à ACK num = k + 1 | seq = j à Client
Serveur à ACK num = k + 1 | seq = j | FIN à Client
Client à ACK num = j + 1 | seq = k + 1 à Serveur
Remarque : Vous pouvez vous demander pourquoi le serveur n’émet pas juste après avoir reçu le paquet FIN du client un paquet ACK+FIN pour signaler en un seul paquet qu’il accepte la fin de connexion du client et que lui aussi décide de fermer sa connexion. Seulement pour simplifier l’étude, nous avions un envoi de données unidirectionnel. La fermeture s’est donc effectuée canoniquement. Mais il se peut, lors d’une communication bidirectionnelle, que l’une des parties ait fini d’émettre avant l’autre. Elle va alors envoyer un paquet FIN pour faire savoir à l’autre qu’elle a fini d’émettre. La machine réceptrice du paquet FIN, va acquitter le paquet, puis continuer ses envois sans que cela ne gêne l’envoi. Il faut noter que la machine réceptrice ne peut plus envoyer de données, puisqu’elle a envoyé le paquet FIN : la connection n’est plus établie que dans un sens. Une fois que toutes les données vont être envoyées, la machine finissant son envoi va alors le signaler à l’autre par un paquet FIN, que la machine destinataire acquittera. Ceci marque la fin de la connection. Donc les fermetures respectives doivent se dérouler en deux échanges chacune pour garantir un fermeture de connexion « propre ».
2. Clôture brutale
Ce type de fermeture est exceptionnel, et ne doit arriver le moins possible. Il faut préférer les fermetures cordiales. Mais dans certains cas elles sont impossibles. Ce principe consiste à envoyer un paquet avec le flag RST. Ceci aura pour effet de réinitialiser immédiatement la connection.
Après avoir observé les deux protocoles de transport radicalement différents que sont TCP et UDP, nous pouvons conclure que leur choix dépend de ce qu’un développeur de logiciel souhaite : s’il souhaite de la sécurité (authentification + confidentialité) soit il veut un protocole applicatif relativement simple et léger, dans ce il fait confiance au mode de connection TCP. Ou alors, il opte pour UDP, dans ce cas il développe un protocole applicatif robuste, capable de gérer les différents points de sécurité. Au contraire, s’il n’a que faire de la sécurité, que seul compte la rapidité et le faible coût en bande passante, alors il choisira UDP sans aucun doute.